
Перенеся текстовый файл из одной операционной системы в другую, вы неожиданно можете обнаружить, что кириллический или даже английский текст, что также не исключено, превратился в кракозябры. Так бывает, когда в одной ОС при создании файлов используется одна кодировка, а в другой системе – другая. Если вам известна исходная кодировка, вы можете выбрать ее в текстовом редакторе другой операционной системы.
Содержание статьи:
Но далеко не факт, что это поможет восстановить корректное отображение текста.
Например, во встроенном в Puppy Linux текстовом редакторе Geany манипуляции с кодировками скорее всего ни к чему не приведут. Тем более, если вы не помните или не знаете, в какой кодировке создавался файл. Тем не менее, выход из ситуации есть и очень простой.
Онлайн декодеры
С распознаванием кодировок вполне успешно справляются специализированные онлайн-сервисы – декодеры. Для определения кодировки они используют комбинации различных методов, как то: частотный анализ и анализ диапазона символов, распознавание сигнатур, эвристику, метод проб и ошибок, когда программа сравнивает полученные результаты и выделяет наиболее осмысленный вариант, и так далее.
Вот некоторые из наиболее популярных сервисов:
Online-Decoder.com – декодер с поддержкой русского, болгарского, греческого, тайского языков, а также иврита. Поддерживает автоматическое и ручное распознавание, выбор наилучшего результата пользователем.
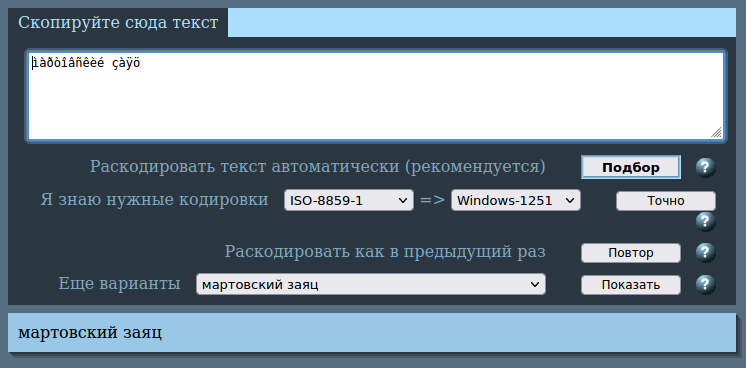
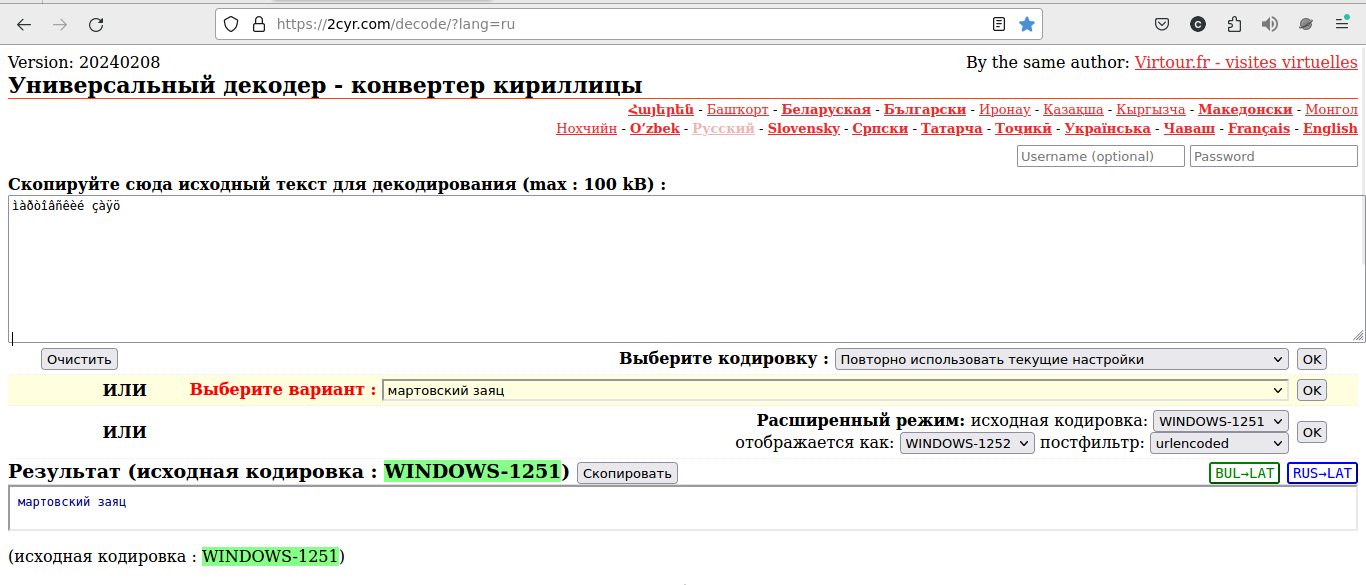
2cyr.com/decode – функциональный онлайн дешифратор, отличающийся поддержкой более 20 языков и постфильтрацией. Если результат расшифровки окажется неудовлетворительным, можно открыть выпадающий список «Выберите вариант» и поискать наиболее осмысленный текст.
Нейронные сети
С тем же успехом для определения и преобразования кодировки можно использовать нейронки Gemini и ChatGPT. В нашем случае Gemini расшифровала текст, но так и не смогла точно ответить на вопрос, какая именно кодировка использовалась, предоставив несколько вариантов на выбор.

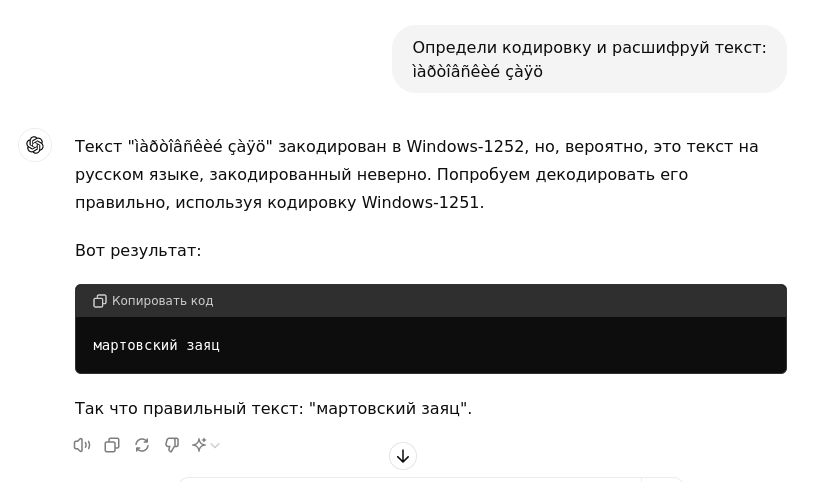
ChatGPT справился с задачей успешнее, сразу распознав кодировку и расшифровав текст. Кстати, ChatGPT может дешифровать частично перекодированный или смешанный текст, главное правильно сформировать запрос.
Когда раскодировать текст не получится
Увы, даже самый лучший декодер не гарантирует стопроцентный положительный результат.
Если исходный текстовый файл был поврежден, при создании файла использовалась редкая или устаревшая кодировка, вероятность успешного декодирования будет невысокой. Вряд ли также удастся декодировать текст, состоящий не из кракозябров, а из знаков вопроса. Так часто бывает, когда данные были сохранены с ошибками кодировки. В этом случае компьютер не сможет правильно интерпретировать используемые в тексте символы.




Добавить комментарий